Programação
-
Aula 4
Explorando dados – Medidas de posição, dispersão e concentração
-
Reveja os apontamentos utilizados pelo Prof. Carlos Tadeu da Silva, do Departamento de Matemática e Estatística da ESALQ, para apresentar as medidas de dispersão. Considere, principalmente, as explicações apresentadas para definir:
Desvio Padrão
- dá uma idéia do desvio médio absoluto com relação à média de um conjunto de observações (amostra)
Variância
- é o quadrado do desvio padrão
Coeficiente de Variação
- mede a dispersão relativa amostral, e é resultado de dividir o desvio padrão pela média da amostra [Desvio Padrão/Média * 100]
- dá uma idéia do desvio médio relativo com relação à média de um conjunto de observações (amostra)
Nota importante
Desvio padrão e erro padrão não são a mesma coisa. Vamos entender a diferença.
O desvio padrão é uma medida de precisão da média amostral. Ou seja, é uma medida que indica a dispersão dos dados dentro de uma amostra com relação à média da amostra. Assim sendo, quando menor o valor do desvio padrão, mais homogênea é a amostra.
Já o erro padrão é uma medida de variação de uma média amostral em relação à média da população. Para se chegar a uma estimativa do erro padrão, basta dividir o desvio padrão pela raiz quadrada do tamanho amostral.
Para que serve o erro padrão?
Através do erro padrão, pode-se estimar um intervalo de confiança para a média populacional a partir da média amostral calculada. Assim sendo, se estabelecermos, por exemplo, um nível de significância de 5%, é possível construir um intervalo de confiança que terá 95% de probabilidade de conter a média real da população.
Estude o caso ilustrado no quadro abaixo que analisa o volume observado nas embalagens de uma certa marca de suco de laranja.

Para cálculo do intervalo de confiança o erro padrão é multiplicado pelo percentil associado ao nível de significância observado em uma distribuição normal padrão, ou seja, que apresenta média 0 e desvio-padrão igual a 1.
Para o nível de significância de 5%, esse valor é de 1,96. Portanto, podemos concluir para o exemplo que existe a probabilidade de 95% do intervalo de 467,4 a 532,6 mililitros (500 ± 1,96 * 16,7) conter a média do verdadeiro volume das garrafas de suco de laranja.
Da mesma forma, pode afirmar que o intervalo entre 496,3 e 503,7 ml (500 ± 1,96 * 1,9) tem probabilidade de 95% de conter o volume médio de suco de laranja em todas as garrafas produzidas pelo fabricante.
A diferença entre desvio padrão e erro padrão
É muito frequente a confusão entre os conceitos de erro padrão e desvio padrão. Apesar de ambos tratarem da variação da média, são conceitos bem diferentes entre si.
O desvio padrão, como vimos, trata de um índice de dispersão da amostra em relação à média, enquanto o erro padrão é uma medida que ajuda a avaliar a confiabilidade da média calculada.
-
Procure no Excel as funções estatísticas que calculam as medidas de tendência central e de dispersão estudadas nos apontamentos resumidos nas primeiras seções desta página.
Considere os dados já explorados em sala de aula e que foram coletados pela empresa ECOLOG e que mostram a grande diversidade de espécies arbóreas da Amazônia (clique AQUI para download da planilha com esses dados).
Identifique as três espécies de maior ocorrência (as mais frequentes) e para cada uma delas, em uma planilha Excel, calcule as referidas medidas de tendência central e de dispersão. Organize esses resultados em um quadro, converta para PDF e submeta a sua tarefa seguindo as seguintes instruções.
Tarefa (T02)
A sua tarefa deve ser entregue no formato PDF, clicando no link disponível na primeira linha desta seção.
Tarefas entregues em outros formatos (doc, xlx, ppt etc.) serão desconsideradas.
Nomeie o seu arquivo PDF usando o seguinte padrão:
T02_<NoUSP>.pdf (use o seu número USP para identificar a sua tarefa)
-
A Curva de Lorenz e o Índice de Gini
Considere p o valor da proporção acumulada da população até certo nível e φ o valor da correspondente proporção acumulada de uma variável dessa população (por exemplo: renda, escolaridade etc.). Os pares de valores (p, φ) para os diversos níveis, definem pontos num sistema de eixos cartesianos ortogonais que se unidos geram a curva de Lorenz ilustrada na figura abaixo:
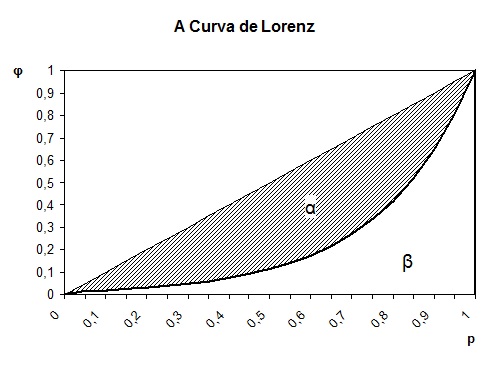
A curva de Lorenz mostra como a proporção acumulada φ da variável da população varia em função da proporção acumulada (p) da população, com os indivíduos ordenados de acordo com valores crescentes da variável. A área hachurada α, compreendida entre a curva de Lorenz e a bissetriz no gráfico acima, é denominada área de concentração.
Se imaginarmos uma perfeita distribuição da variável da população, por exemplo renda, onde todos recebem a mesma quantidade, teremos que cada proporção p da população recebe exatamente a mesma proporção da variável, ou seja, φ = p. Nesse caso, a curva de Lorenz se reduz à própria bissetriz, que por isso se denomina “linha de perfeita igualdade”, e α = 0.
Vamos agora imaginar uma distribuição com máxima desigualdade, isto é, numa população com n indivíduos, apenas um deles detém toda a variável medida (por exemplo, renda) e os demais n-1 nada possuem. Nesse caso, é fácil verificar que α se torna igual a 0,5.
Por definição, o índice de Gini (G) é a razão entre a área de concentração α e o valor 0,5. É possível demonstrar que, para distribuições discretas, essa razão pode ser calculada através da seguinte expressão:
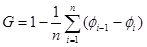
Concentração de terras no Brasil**
Situação cadastral em 02/12/92 (antes): índice de Gini = 0,848
Situação cadastral em 30/11/00 (depois)
** (consideram-se projetos de assentamento; banco da terra ; e xclusão de terras públicas, áreas canceladas por grilagem)
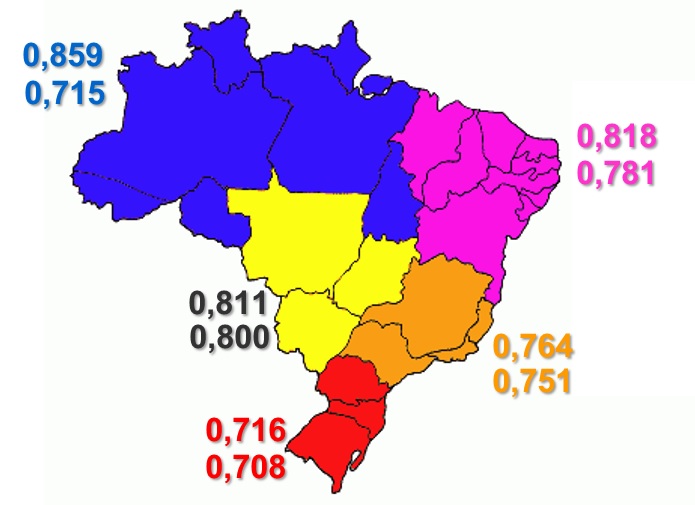
Fonte: Ministério do Desenvolvimento Agrário e Instituto Nacional de Colonização e Reforma Agrária.
-
Este questionário tem apenas uma questão e trata de um único conceito, o índice de Gini.
A questão testa a sua compreensão sobre o significado desse índice.