Indice degli argomenti
-
-
Relatório de 2017 da Computer Weekly
-

Nesta primeira aula apresentaremos a estrutura do curso como um todo, livro texto, e a forma de avaliação. Faremos um breve histórico sobre o interesse geral da academia e de todo o resto da humanidade no conceito de inteligência e sua reprodução por máquinas e mecanismos. Introduziremos o conceito de agente inteligente, que é fundamental para a inteligência de máquina, seja embarcada ou distribuída em sistemas inteligentes.
O curso está dividido em uma parte teórica e uma parte prática. Gostaríamos de ter a capacidade de desenvolver pequenos programas inteligentes (lidaremos com software somente). A parte prática será trabalhada via este site, embora algumas das aulas "teóricas" tratarão de exercícios, exemplos práticos, e programas. Entretanto, não será possível inserir um curso de programação lógica em uma disciplina com dois créditos apenas. Portanto usaremos tutoriais e uma referência bibliográfica de apoio (Programming in Prolog, W. F Clocksin, C.S. Mellish, Springer, 2003). Um tutorial online para programação será usado (veja link abaixo).
Para programação, uma versão online do SWI Prolog será usado (ver link abaixo). Com isso eliminaremos problemas de instalação, particularidades com sistemas operacionais, etc.
-
Link para ambiente de programação em Prolog.
-
Tutorial para programação em Prolog
-
-

Reunião no Dartmouth College para discutir a "inteligência Artificial".
Nesta aula vamos começar a tratar da resolução de problemas de forma inteligente. A idéia é capacitar máquinas (computadores) para resolver problemas, uma capacidade normalmente associada a sistemas (humanos) inteligentes. Já vimos as limitações que esta inteligência de máquina pode ter, mas ainda assim, seria uma evolução tecnológica considerável ter sistemas capazes de fazer planos, aprender analizar padrões ou dar apoio à decisão. Ao invés de introduzir este tópico de maneira formal vamos abordá-lo (inicialmente) de forma simples com alguns problemas que podem ser tratados com "regras", agindo sobre uma base de fatos.
Podemos sofisticar o nível de abstração destas regras (a distância para os "fatos") e também o número de regras tornando os programas mais complicados e mais "inteligentes". Mas é ainda possível ver as limitações e também as possibilidades que surgem para aplicações, especialmente em automação. Aproveitamos para introduzir a linguagem Prolog e exercitar a sua aplicação no Swish SWI Prolog.
Terminaremos propondo um avanço na forma de resolver problemas que nos aproxima ainda mais da modelagem estado-transição (ou dos "transition systems"). Novamente vamos entrar neste assunto de forma prática para colocar mais tarde a abordagem formal. A aplicação no momento seria um sistema automático para jogos.
Cerca de 30% da emissão de passagens em companhias aéreas é feita usando Prolog.
Uma matéria divulgada pela SICStus Prolog, que faz um ambiente de programação Prolog onde se pode produzir programas de interesse de mercado. Veja o link a abaixo...

-

Vamos agora avançar um pouco no entendimento dos tipos principais de problema e nos métodos para trata-los. A diferença entre um sistema algorítmico normal e um sistema inteligente está nos métodos de resolução de problemas e notadamente (no nível de abordagem deste curso) na capacidade de automatizar a resolução de problemas. Vamos portanto focar nos aspectos conceituais desta automação e nos algoritmos de apoio, o que começa com os algoritmos de busca. Veremos que a ligação entre os métodos de aplicação da inteligência artificial na engenharia (especialmente planning) e a base conceitual da IA começa pelos algoritmos de busca e especialmente de busca informada. Estes serão melhor explorados na aula que vem.
Devemos nos preparar para o primeiro trabalho em grupo, e portanto a turma deverá se dividir em grupos de quatro. Também colocaremos um novo chat para que todos possam colocar as dúvidas e também a formação dos grupos. Cada grupo deve propor um "problema" a ser resolvido com um programa inteligente baseado em regras e busca não informada. Faz parte do exercício a definição do problema e o discernimento sobre o que consiste de fato em uma aplicação prática da IA (aplicações simples, por favor!).
-
Duvidas e formação dos grupos Chat
Neste chat trataremos das duvidas surgidas na resolução dos exercicios, da formação dos grupos e da proposição dos problemas para o primeiro trabalho de grupo.
-
Formação de grupos para o primeiro trabalho Forum
Os alunos devem se organizar em grupos de quatro (devemos ter seis ou sete grupos) e escolher uma aplicação ou problema para ser "resolvido" pela abordagem de resolução de problemas em IA.O prazo de entrega do problema resolvido é de um mês contando a partir da próxima aula dia 29/08.
-

Vamos retornar à nossa discussão sobre resolução de problemas, agora considerando a diferença entre a resolução de problemas por humanos e por máquinas. Aproveitaremos então para introduzir os sistemas baseados em regras, e os sistemas especialistas agora avançando na discussão sobre os métodos básicos de inferência. Um sistema especialista é composto por três elementos básicos: a interface com o usuário, a base de conhecimento e a máquina de inferência. A primeira não será objeto deste curso, embora seja muito importante e às vezes crucial para o sucesso comercial de várias aplicações de IA, como mostraremos na aula. A segunda é justamente o objeto da discussão na aula de hoje. A terceira, será parcialmente delegada para a máquina prolog e para a programação, e será discutida com mais detalhes mais adiante.
Nas aulas seguintes discutiremos a representação de conhecimento, e em seguida os algoritmos de busca e busca informada. Em paralelo discutiremos as técnicas de programação em Prolog e a implementação do primeiro trabalho.
Como leitura suplementar acrescentamos um artigo de Allen Newel e Herbert Simon sobre as diferenças entre "human problem solving and machine problem solving". Os que quiserem explorar mais este tema são fortemente aconselhados a ler este artigos. Mesmo para os demais o artigo é muito interessante e instigante e complementa com mais detalhes o tópico de discussão desta aula.
-

Na aula passada discutimos conceitualmente as estratégias de resolução de problemas por humanos e máquinas, com o objetivo de fazer uma clara distinção entre os dois processos e deixar claro as limitações da máquina (no caso o computador no seu modelo von Neuman sequencial) para tratar de processos normalmente associados a humanos. A proposta de ter um método geral para resolução de qualquer problema (que discutiremos mais detalhadamente nas próximas aulas) está ligado a esta referência (humana) e é uma discussão antiga, como vimos no histórico das primeiras aulas.
Partiremos do paradigma estado/transição para tratar do problema da resolução de problemas por máquinas, tomando como exemplo o exercício que foi dado para as equipes recentemente formadas. Discutiremos em primeiro lugar os algoritmos de busca não-informada e nas aulas seguintes os algoritmos de busca informado, o conceito de heurística e conhecimento tácito, muito importante para a elaboração de sistemas especialistas. Lembrando que estamos discutindo os conceitos clássicos da IA.
Apresentaremos algumas "boas práticas" no desenvolvimento de software para inteligencia artificial, novamente tomando como base o exercicio-programa.
-
Slides da Aula5
-
Vejam um livro muito interessante da Pamela McCorduk, professora dos cursos de Inteligência Artificial em Stanford.
-
-
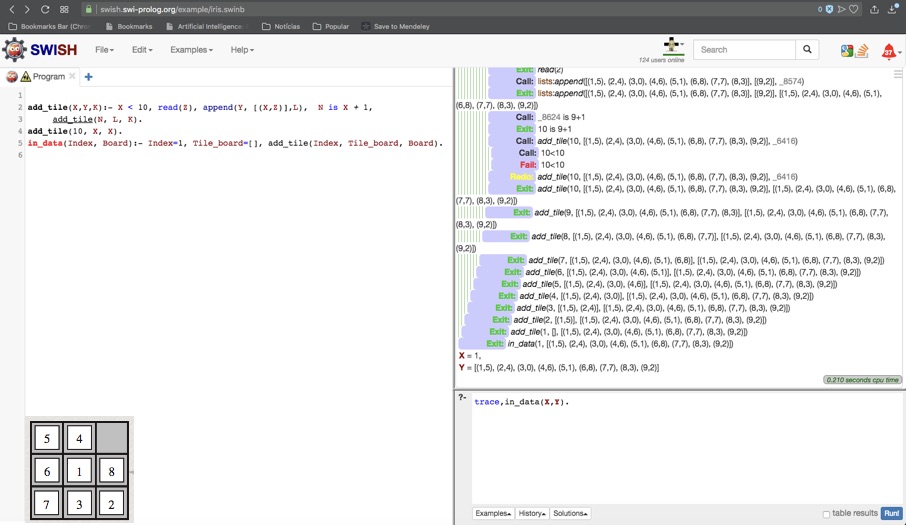
Nesta aula vamos fazer um breve parêntese na discussão dos algoritmos de busca para inserir um tópico pertinente à implementação, que é a introdução de estruturas, como lista e árvore. Estas estruturas são implementadas de maneira mais direta nas linguagens procedurais, mas em Prolog, como em outras linguagens declarativas interpretadas (como Lisp, APL, etc.) as estruturas são a base para processos eficientes de chamada recursiva, como veremos nos exemplos.
A razão para anteciparmos a discussão sobre implementação é municiar as equipes para o andamento do trabalho de grupo, deixando-os livres para pensar somente o núcleo inteligente do projeto e não nos aspectos periféricos que poderiam demandar habilidade de programação em Prolog, o que certamente não é o caso da maioria. Por outro lado manteremos estes procedimentos bem simples, mesmo sabendo que existem opções mais eficientes e/ou mais elegantes para implementar a mesma coisa. A prioridade é que seja mais fácil de entender o programa em caso de ser preciso fazer o "tracing" para debugar o código.
Prosseguiremos depois com a discussão qualitativa dos métodos de busca já que sua implementação começará a ficar mais clara.
Nesta aula também faremos uma breve discussão sobre o cronograma de execução do trabalho em grupo.
-
Slides da Aula6
-
-

Vamos a partir desta aula mudar o foco da discussão sobre os algoritmos de busca usados em IA da busca clássica não-informada para a busca informada, onde se pode usar heurísticas obtidas de conhecimento tácito ou explicito para orientar a escolha do caminho na árvore de busca. Esperamos portanto obter uma melhor performance, comparado aos métodos clássicos e assim justificar o uso de IA para problemas que têm um custo proibitivo por métodos convencionais, ou mesmo que não chegam a uma resposta, utilizando métodos otimizados. A barganha é portanto obter uma solução próxima do ótimo mas em um tempo aceitável.
Começaremos a discussão pelo best-first, e aplicaremos este algoritmo para um exemplo já bem conhecido que o 8-Puzzle, ou o jogo dos tiles, que é o exercício em grupo que estamos considerando. Aproveito para lembrar que o milestone para este exercício, que seria hoje foi adiado de uma semana, em função de termos perdido a aula passada.
-
Transparencias da Aula 7
-
Este é o milestone para o primeiro trabalho em grupo. Faça o upload até a data limite (10 de outubro próximo) da descrição da heuristica que deverá usar no seu trabalho com a respectiva justificativa de performance (porque e como irá acelerar a busca). A coleta funciona até a meianoite do dia 10/10.
-
-

Vamos agora introduzir o algoritmo de busca A* e suas propriedades. Temos já um bom resumo dos algoritmos de busca não-informada, contida no material da UVA disponibilizado no site depois da aula passada. Agora daremos um passo definitivo para ter um algoritmo de busca otimizante com performance exponencial. No entanto, dependendo do número de estados e da qualidade da heurística uma resposta (se existir) pode ser obtida em um tempo razoável, como veremos na resolução de alguns jogos. Vamos nos concentrar novamente no 8-Puzzle ou jogo dos tiles, para dar mais suporte ao trabalho em grupo.
Também apresentaremos os detalhes da competição já marcada para o dia 31 de outubro próximo.
-
Noticia divulgada pelo Select Game, um site especializado em noticias sobre games, com conteúdo técnico sofrível, mas sempre bem cuidado e sem exageros.
-
Até aqui a "inteligência" foi transformada em programas algorítmicos baseados em busca clássica ou informada. Se por um lado há de fato uma nuance inteligente nestes programas, fica a impressão de que esta inteligência está de fato na cabeça do programador/designer e não no sistema computacional que executa estes algoritmos. Vamos deixar de lado (pelo menos no que diz respeito ao escopo direto da disciplina, mas podemos levantar a discussão via forum) sobre o limite de quanto se pode "transferir" um processo racional inteligente para a máquina e quanto deste processo depende de um programador e de um usuário humano. Mas vamos de fato aumentar a complexidade da Base de Conhecimento e começar a trabalhar com a programação lógica (o que implica em introduzir formalismo lógico ao que estamos fazendo).
Portanto nesta aula começaremos a discutir os processos de inferência com uma breve introdução conceitual ao que se chama Teoria de Modelos em matemática, concentrando a abordagem na dedução de sentenças à partir de uma base de conhecimento. Esta base pode estar em Lógica de primeira ordem, mas vamos restringir a representação formal à Lógica de Predicados. Na aula que vem vamos explorar uma representação mais específica em Cláusulas de Horn e trabalhar mais diretamente com Programação Lógica.
-
Slides da aula 9
-
-
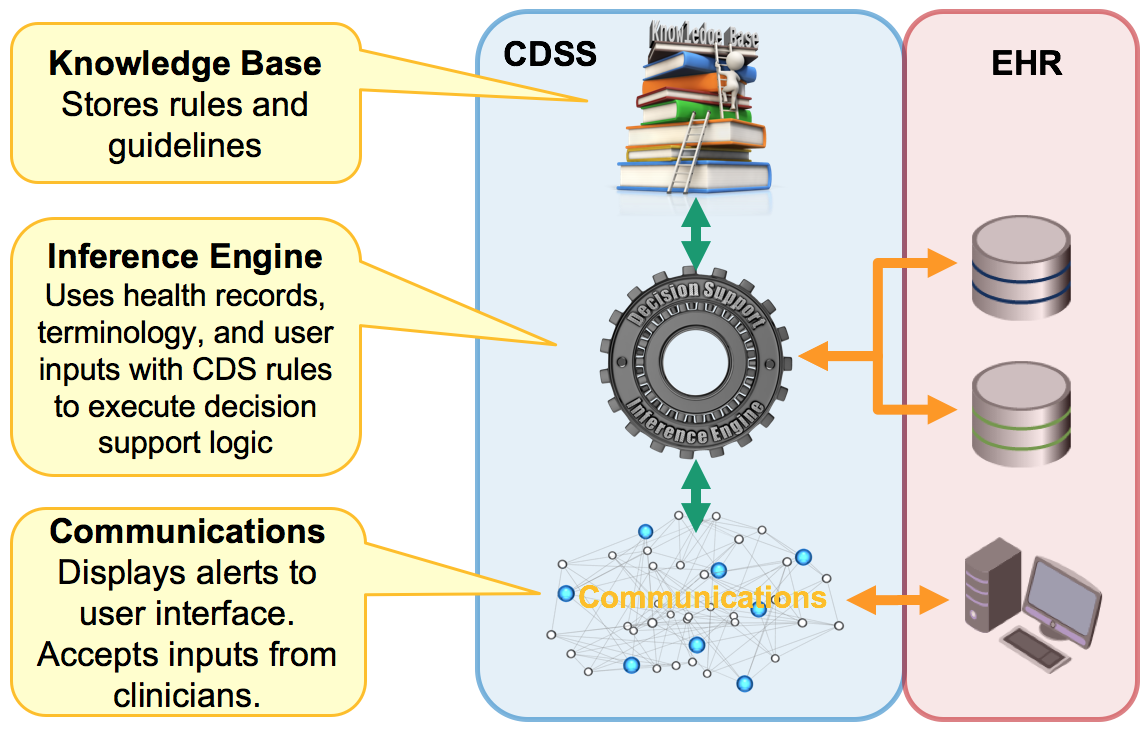
Nesta aula vamos discutir os mecanismos de inferência, isto é, como poderemos transformar a inferência lógica discutida na aula passada em um algoritmo (em Prolog, na nossa abordagem) e ter um sistema inteligente mais convincente. As aplicações são várias e você podem ver na figura acima um CDDS (Clinical Decision Support System) que, baseado em regras de diagnóstico de quadros clínicos e uma máquina de inferência, de auxiliar médicos (humanos) a, baseado no prontuário médico dos pacientes e de estatísticas de ocorrência de doenças a partir de sintomas (os dados "sensoriais" de análise neste caso) podem ajudar no diagnóstico pela ação de uma máquina de inferência. A expectativa é que sistemas como estes possam funcionar na triagem e encaminhamento de pacientes para clinicas, hospitais, etc. evitando desperdício de recursos e atribuição precipitada de recursos. Por outro lado o encaminhamento evitaria filas e uma demora que pode ser fatal ou pelo menos bastante sofrida.
Existem vários casos onde uma máquina de inferência poderia ser de grande utilidade prática. O que nos interessa nesta aula é focar neste mecanismo, baseado no Modus Ponens Generalizado. Usando esta abordagem e reduzindo a abordagem lógica e os quantificadores universal e existencial a uma abordagem mais simples, baseada em cláusula de Horn, teremos a base para a programação lógica e para construir, sobre uma máquina "buit-in" programas lógicos que funcionam com base no backward chaining e podem portanto "provar" que uma determinada base de conhecimento é modelo para uma dada proposição. Com iso poderemos deduzir desde o melhor caminho para um agente no "Mundo de Wumpus" até um diagnóstico médico. Claro estamos falando de programas lógicos de tamanho e complexidade bem distintas.
Assim, damos mais um passo na direção dos sistemas de planejamento (que trataremos depois da competição que será na aula que vem). Estão todos prontos?
-

Hoje realizamos a nossa competição de diferentes implementações e otimizações do algoritmo A* para resolver o jogo de tiles, um exemplo clássico do livro texto. As regras foram anunciadas nas aulas anteriores e teremos três rodadas com diferentes configurações iniciais dos tiles. O critério é o tempo que roda o algorítmo e estamos supondo que todos usariam a mesma rede Eduroam/PoliSemFio, que é a opção institucional. Portanto as condições são em princípio iguais para todos.
A avaliação é feita em duas etapas, uma pela nota da competição, e outra pela descrição do algoritmo e "tracing" da busca reaiizada (a descrição dos custos e dos estados intermediários entre o estado inicial e final). A nota da competição é dada pelo resultado (do primeiro ao quinto lugar (de 1 a cinco pontos em ordem crescente), e valendo cinco pontos se a busca terminar com bom resultado.
Realizada a competição o resultado foi o seguinte para nota da competição (as notas foram normalizadas, de modo que a nota mais alta (nove) passou a ser (dez) e as demais forma elevadas para manter a mesma relação entre os competidores):
Nota da competição grupo 1a. rodada 2a. rodada 3a. rodada Media das rodadas Nota normalizada Grupo 1:
Alyson, Alexandre
Eduardo, Vitor
7 10 9 8,7 9,7 Grupo 2:
Alex, Gabriel Ferreira
Lucas, Thiago
10 9 8 9 10 Grupo 3:
Gabriel Tutia, Lucas
Pedro, Samuel
9 8 10 9 10 Grupo 4:
Gustavo, Luiz Guilherme,
Alessandro, Gabriel Negre
8 7 7 7,3 8,3 Grupo 5:
Gabriel Yida, Danilo,
Vinicius
6 6 6 6 7 -
Competição
-
Faça o upload da descrição do seu algoritmo
-
-

A atividade de planejamento é geralmente relacionada com processos racionais inteligentes, e historicamente, marcou o desenvolvimento da humanidade e o seu caminho até os dias atuais. Nos dias atuais continua sendo uma atividade de grande destaque, e presente em qualquer atividade que pretenda ser eficiente, prática e que evite percalços. Há portanto uma grande demanda para sistemas inteligentes de planejamento sejam eles baseados em técnicas que classificamos como clássicas, seja baseado em estatística, cadeias de Markov, acopladas a processos de incerteza e/ou a aprendizado de máquina. Seja como for a demanda só aumenta e o futuro da automação está intimamente ligado com a capacidade de prover os processos automatizados da capacidade de planejar.
Nesta aula vamos introduzir os problema de planejamento, sua separação com o ambiente onde o plano vai ser inserido ou realizado (que deve gerar mais restrições ao processo). O ponto importante é no entanto a relação que existe entre os processos de planejamento e a modelagem estado-transição, que de fato vai inspirar o processo e a linguagem de planejamento mais conhecida, o STRIPS (Stanford Research Institute Problem Solver). O SRI se destacou durante os últimos 50 anos na pesquisa em Inteligência Artificial e foi o berço do que chamamos planejamento clássico. O interesse maior foi sempre ter um planejador genérico, independente de domínio, que pudesse ser embarcado em sistemas autônomos, como o robô Shakey mostrado na figura acima.
Segundo trabalho do curso Nesta aula iniciamos o segundo trabalho do curso que consiste em, conservando as equipes atuais, escolher uma aplicação clássica de Inteligência Artificial baseada nos métodos clássicos (sistemas especialistas, sistemas de diagnóstico, controle inteligente, planejamento) e pesquisar como esta aplicação foi programada, usando quais métodos, o que faz, alguma noção de sucesso e de ter alcançado os resultados esperados. As informações podem ser obtidas na internet, em contato com quem usa a aplicação e eventualmente com a empresa que fez o sistema. Elas costumam responder aos e-mails. O objetivo do trabalho é que vocês tenham uma noção mais precisa das aplicações da IA ligadas à engenharia e em especial à automação.
O milestone para este final de semana é ter escolhido a aplicação e postar arquivo PDF com o nome dos membros da equipe (se houver desistências do curso nomes podem ser retirados da lista), e com a descrição da aplicação escolhida. Enviarei um feedback no domingo via a página da disciplina. -

Nesta aula vamos entrar em mais detalhes sobre o STRIPS e consequentemente sobre os métodos de planejamento automático, antes de tratar os algoritmos de planning propriamente. Assim, os pressupostos do STRIPS são revistos baseado em um artigo do Fikes e Nilsson publicado em 1993 pela revista Artificial Intelligence, uma das mais destacadas na área. O artigo faz um retrospecto do projeto que consolidou o STRIPS, mostrando o esforço de grandes pesquisadores da área como R. Fikes, N. Nilsson, E. Sacerdoti, P. E. Hart, B. Raphael, e outros, envolvidos no projeto do robô Shakey (mostrado na figura que ilustra a aula passada). O objetivo é destacar a força conceitual do STRIPS e sua base do General Problem Solver (GPS), proposto por Allen Newel e Herbert Simon, que valeu a ambos o Turing Award. Por outro lado é preciso também mostrar as fragilidades do método que se foram importantes para simplificar o problema e direcionar o foco para o "STRIPS monitor" que efetivamente "prova o teorema" de como se pode ir do estado inicial para o estado final, também podem conduzir a resultados inesperados.
A anomalia de Sussman ilustra uma destas fragilidades e foi apresentada por Gerald J. Sussman na duarante a elaboração da sua tese de doutorado em 1973, orientada por Marvin Mynsky no MIT. Ao contrário da maioria dos grandes pesquisadores citados Sussman está vivo e ainda atuante no CSAIL (Computer Science and Artificial Intelligence Lab) do MIT.
Na verdade embora seja importante destacar as limitações do STRIPS isso não afeta os planejadores automáticos atuais e todos podem evitar facilmente (mesmo os planejadores dados como exercício para alunos de IC já fazem isso com facilidade) a anomalia de Sussman, mas a detecção destas anomalias servem para conduzir a busca por novas abordagens (ainda baseadas no STRIPS) para o problema do planejamento automático. Apresentaremos no final da aula uma destas abordagens voltadas para o tratamento do problema de planning com técnicas de Knowledge Engineering.
-
slides da aula13
-
R. E. Fikes, N. J. Nilsson, STRIPS, a retrospective, Artificial Intelligence, 59, pp. 227-232, Elsevier, 1993
-
-

Nesta aula continuaremos a discussão sobre os principais algoritmos (clássicos) de planejamento automático fazendo um link para a demanda atual e o que seria necessário para tratar destes problemas ainda que inspirado nestes algoritmos clássicos. Começaremos pelo tratamento do problema da não-linearidade discutido na aula passada, que como dissemos, foi completamente superado pelos algoritmos que se seguiram à sua descoberta. O NONLIN (Aston Tate) é um destes algoritmos, seguido do NOAH, Sipe e O-Plan. Para estes a não-linearidade se junta à abstração e abordagem hierárquica. Na verdade o tratamento hierárquico é visto nos dia de hoje de forma diferente, como veremos na próxima aula. Introduziremos brevemente o Graphplan e em seguida discutiremos, como uma preparação para a próxima aula, a possibilidade de relaxar algumas das restrições que caracterizam o STRIPS, analisando as consequências em complexidade e esforço computacional.
Continuaremos esta discussão na próxima aula.
-

Nesta aula vamos finalizar o curso com uma análise do que a IA clássica e em especial os sistemas especialistas e os sistemas de planejamento e escalonamento podem propiciar para atender a demandas atuais e futuras, ao lado de outras técnicas que não estão no escopo desta disciplina, como os sistemas de apoio a decisão, machine learning e os algoritmos evolutivos, que foram brevemente mencionados durante o curso. Em especial é preciso ver as vantagens de flexibilidade e uso mais intensivo das heurísticas e algoritmos de busca que podem agora ser incrementados com mecanismos de abstração e hierarquia, bem como com a introdução do tempo como parâmetro ou como variável. A introdução do model-checking (com o sem tempo) é uma possibilidade concreta em sistemas reais.
Em especial vamos considerar a possibilidade de usar Inteligência Artificial no contexto da Industria 4.0, onde existem os principais desafios de automação desta primeira metade de século. A introdução dos serviços com base conceitual da produção amplia bastante o espaço para sistemas de workflow e do direcionamento inteligente de processos para os novos sistemas produtivos. Em especial o acoplamento com o cliente e o alongamento deste acoplamento para toda a vida útil do produto/serviço muda o relacionamento com este cliente e viabiliza os novos aplicativos inteligentes. Isso além dos demais serviços do dia-a-dia.
Nota da competição grupo Nota da competição Nota da documentação Media Segundo trabalho Prova Grupo 1:
Alyson, Alexandre
Eduardo, Vitor
9,7 9 9,35 Grupo 2:
Alex, Gabriel Ferreira
Lucas, Thiago
10 10 10 Grupo 3:
Gabriel Tutia, Lucas
Pedro, Samuel
10 10 10 Grupo 4:
Gustavo, Luiz Guilherme,
Alessandro, Gabriel Negre
8,3 5 6,65 Grupo 5:
Gabriel Yida, Danilo,
Vinicius
7 0 3,5 -
Uma discussão interessante sobre o papel da IA na engenharia moderna
-

Teremos nesta aula o exame final da disciplina. Vocês podem usar até os 100 minutos de aula para resolver as questões, sem uso de aparelhos eletrônicos ou da rede. O exame não é uma competição, muito menos entre vocês e eu, portanto não tem novidade, trata do que foi discutido durante a disciplina envolvendo técnicas de Inteligência Artificial, programação lógica básica, algoritmos de busca e seu uso em planejamento, o STRIPS, e aplicações práticas da IA. O histórico da Inteligência Artificial, embora importante para o entendimento do contexto, não será "cobrado" no exame. Sem dúvida é bom estudar e relembrar as coisas, mas para quem acompanhou o curso será um fechamento natural e sem muito stress. A idéia é exatamente esta!
A composição da média final será feita do seguinte modo: a nota final da competição sobre o A* aplicado a jogos e do segundo trabalho (aplicação prática da IA clássica) vão compor uma média parcial. Esta média e o exame compõem uma média aritmética. Infelizmente não há mais prazo para entregas atrasadas e teremos que fechar as notas para cumprir o nosso prazo com a coordenação da graduação.
