Abschnittsübersicht
-
Aula 5
Medidas de posição, dispersão e concentração
-
Medidas que expressam a natureza de certas variáveis aleatórias
A análise exploratória da dados envolve a exploração dos valores observados de uma variável ou parâmetro de uma população. Na série de dados climáticos, temperatura, precipitação etc. são parâmetros extraídos de uma população de possíveis intervalos de tempo (dias, por exemplo) num determinado local (estação meteorológica da ESALQ). Vimos o caráter estocástico (aleatório) desses parâmetros. Ou seja, vimos que a ocorrência de um certo valor para um certo parâmetro não é determinística (i.e., não pode ser determinada com exatidão). Esses valores simplesmente variam, e é impossível prever o seu valor exato!
Por variarem, nos referimos a esses parâmetros como aleatórios ou estocásticos. Conhecer todos os valores possíveis de um parâmetro que caracteriza uma população exigiria conhecer a população inteira. Isso é geralmente impossível (quando infinita, por exemplo) ou muito difícil de ser obtida (como o peso de todos os habitantes vivos do planeta num determinado instante). Todavia, medições amostrais podem ser realizadas para que possamos descrever o comportamento desses parâmetros da população.
A partir de agora faremos uma distinção entre parâmetros, como medidas descritivas de uma população, e estatísticas, que são medições descritivas extraídas de uma ou mais amostras. Essa distinção é necessária para que possamos lidar com os casos em que não é possível calcular diretamente o valor dos parâmetros de uma população, mas podemos calcular as correspondentes estatísticas para amostras retiradas dessa população e, a partir dessas estatísticas, fazer inferências sobre os respectivos parâmetros da população.
Primeiramente, iremos recorrer a medidas de posição (ou tendência central) e de variabilidade. As medidas de tendência central exploram como se concentram as distribuições de frequências dos dados. As de variabilidade descrevem como os dados variam em torno do centro da distribuição.
Medidas de tendência central
Moda- é o valor mais frequente ou provável em um conjunto de observações (podem existir uma ou mais modas no conjunto de observações)
- não é afetada pela existência de observações extremas (valores muito acima ou abaixo dos mais observados no conjunto de dados)
- as modas observadas em subgrupos do conjunto completo de observações não mantém relação com a moda do conjunto completo
- o valor da moda pode variar para diferentes agrupamentos do conjunto de observações
- pode ser definida tanto para dados quantitativos como qualitativos
Mediana- uma vez ordenadas, é o valor central das observações que permite distribuir 50% das observações acima e as demais 50% abaixo desse valor
- existe apenas uma mediana para cada conjunto de observações
- não é afetada pela existência de observações extremas (valores muito acima ou abaixo dos mais observados no conjunto de dados)
- as medianas observadas em subgrupos do conjunto completo de observações não mantém relação com a mediana desse conjunto completo para diferentes agrupamentos dos dados
- o seu valor se mantém razoavelmente estável
- só se aplica para conjuntos de observações quantitativas
Média- é calculada como a média aritmética dos valores em um grupo de observações
- existe apenas uma média para cada grupo de observações
- seu valor é afetado pela existência de observações extremas (valores muito acima ou abaixo dos mais observados)
- as médias de subgrupos do conjunto completo de observações podem ser combinadas para gerar a média do conjunto completo
- só se aplica para conjuntos de observações quantitativas
Medidas de dispersão
Desvio Padrão- dá uma idéia do desvio médio absoluto com relação à média de um conjunto de observações (amostra)
Variância- é o quadrado do desvio padrão
Coeficiente de Variação- mede a dispersão relativa amostral, e é resultado de dividir o desvio padrão pela média da amostra [Desvio Padrão/Média * 100]
- dá uma idéia do desvio médio relativo com relação à média de um conjunto de observações (amostra)
Nota importante
Desvio padrão e erro padrão não são a mesma coisa. Vamos entender a diferença.
O desvio padrão é uma medida de dispersão dos dados dentro de uma amostra com relação à média da amostra. Assim sendo, quanto menor o valor do desvio padrão, mais homogênea é a amostra.
O erro padrão é uma medida de dispersão da média amostral em relação à média da população. Para obtermos uma estimativa do erro padrão, dividimos o desvio padrão pela raiz quadrada do tamanho amostral.
Para que serve o erro padrão?
Através do erro padrão, pode-se estimar um intervalo de confiança para a média populacional a partir da média amostral calculada. Assim sendo, se estabelecermos, por exemplo, um nível de significância de 5%, é possível construir um intervalo de confiança que terá 95% de probabilidade de conter a média real da população.
Estude o caso ilustrado no quadro abaixo que analisa o volume observado nas embalagens de uma certa marca de suco de laranja.
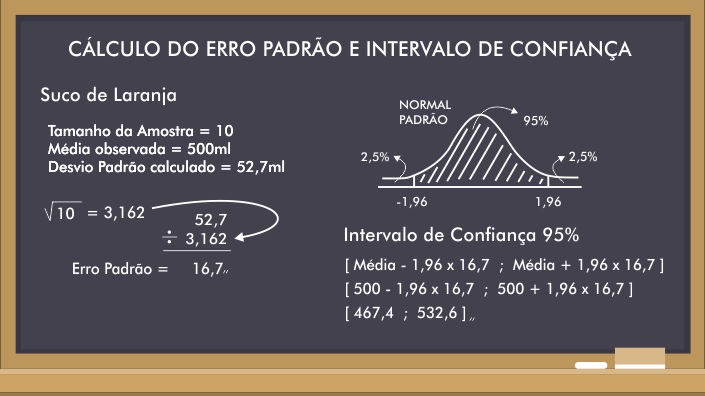
Para cálculo do intervalo de confiança, o erro padrão é multiplicado pelo percentil do nível de significância de uma distribuição normal com média 0 e desvio-padrão 1 ("distribuição normal padrão"). No caso de níveis de significância de 5%, esse valor é 1,96. No exemplo acima, a média do verdadeiro volume das garrafas de suco de laranja está no intervalo entre 467,4 e 532,6 mililitros (500 ± 1,96 * 16,7) com 95% de confiança.
A diferença entre desvio padrão e erro padrão
É muito frequente a confusão entre os conceitos de erro padrão e desvio padrão. Apesar de ambos tratarem da variação de uma média, são conceitos bem diferentes entre si. O desvio padrão é um índice de dispersão da amostra em relação à média da amostra, enquanto o erro padrão é uma medida de dispersão (confiabilidade) da estimativa da real média da população.
Entendendo intervalos de confiança
Assumindo que a variável de interesse numa população apresenta distribuição normal, é possível calcular intervalos de confiança para a estimativa da média calculada a partir de uma amostra extraída dessa população. Vamos considerar o caso em que a variável de interesse numa determinada população tem média 0 e desvio padrão 1. Veja graficamente o que acontece para, diferentes valores de significância, quando extraímos amostras de diferentes tamanhos e quando variamos o número de amostras extraídas.
-
Medida de concentração
A Curva de Lorenz e o Índice de Gini
Considere p o valor da proporção acumulada da população até certo nível e φ o valor da correspondente proporção acumulada de uma variável dessa população (por exemplo: renda, escolaridade etc.). Os pares de valores (p, φ) para os diversos níveis, definem pontos num sistema de eixos cartesianos ortogonais que se unidos geram a curva de Lorenz ilustrada na figura abaixo:
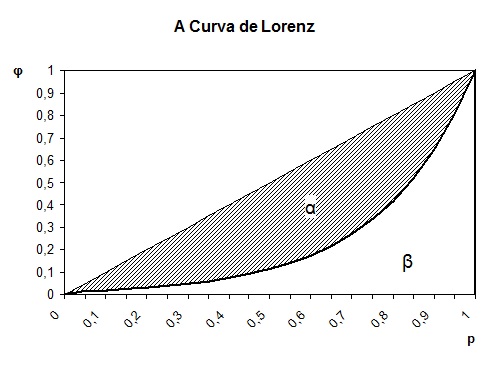
A curva de Lorenz mostra como a proporção acumulada φ da variável da população varia em função da proporção acumulada (p) da população, com os indivíduos ordenados de acordo com valores crescentes da variável. A área hachurada α, compreendida entre a curva de Lorenz e a bissetriz no gráfico acima, é denominada área de concentração.
Se imaginarmos uma perfeita distribuição da variável da população, por exemplo renda, onde todos recebem a mesma quantidade, teremos que cada proporção p da população recebe exatamente a mesma proporção da variável, ou seja, φ = p. Nesse caso, a curva de Lorenz se reduz à própria bissetriz, que por isso se denomina “linha de perfeita igualdade”, e α = 0.
Vamos agora imaginar uma distribuição com máxima desigualdade, isto é, numa população com n indivíduos, apenas um deles detém toda a variável medida (por exemplo, renda) e os demais n-1 nada possuem. Nesse caso, é fácil verificar que α se torna igual a 0,5.
Por definição, o índice de Gini (G) é a razão entre a área de concentração α e o valor 0,5. É possível demonstrar que, para distribuições discretas, essa razão pode ser calculada através da seguinte expressão:
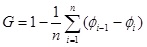
Concentração de terras no Brasil**
O monitoramento da posse da terra e estudos de concentração fundiária no Brasil vêm sendo feitos há décadas. Por exemplo, dados de 1992 apontavam para um índice de Gini geral no Brasil de aproximadamente 0,85. Estudos regionais posteriores, do início dos anos 2000, confirmavam valores próximos a esse de 1992, mas variável entre regiões.

Fonte: Ministério do Desenvolvimento Agrário e Instituto Nacional de Colonização e Reforma Agrária.
Dados mais recentes (2020) e resumidos pelo Imaflora, mostram que a concentração da terra continua alta no Brasil, com índice de Gini igual a 0,73, segundo dados extraídos do Censo Agropecuário do IBGE de 2017. Mais especificamente, em termos absolutos esse levantamento mostrou, por exemplo, que 51.000 propriedades concentravam 47,6% da área agrícola, enquanto pequenos proprietários de até 10 hectares ocupavam apenas 2,3% da terra no Brasil. O índice de Gini segue variável entre regiões e Estados, sendo mais alto no Mato Grosso, Mato Grosso do Sul, Bahia e na região do Matopiba, onde predomina a produção de commodities em grandes imóveis. É mais baixo nos Estados com maior presença da agricultura familiar e maior diversificação da produção, como Santa Catarina e Espírito Santo.

Concentração de renda no Brasil***
O índice de Gini para renda da população brasileira foi de 0,518 em 2023 e repetiu o resultado do ano anterior, quando atingiu o menor patamar da série histórica. Esse resultado se refere especificamente à desigualdade de rendimento médio mensal real domiciliar per capita recebido pela população do país. Houve uma tendência de redução da desigualdade entre 2012 e 2015 (de 0,540 para 0,524), mas a partir do ano seguinte, o indicador aumentou até chegar ao maior valor da série histórica, em 2018 (0,545). Nos anos seguintes, oscilou entre estabilidade, queda e aumento até chegar ao menor nível (0,518) em 2022.
Há diferenças marcantes de distribuição de renda entre as regiões do país. A região Nordeste tem a maior desigualdade seguida de perto pelo Sudeste (0,508), e o Sul apresenta a menor desigualdade (0,454).

*** Fonte: IBGE, consulta 19/04/2024.
Para mais detalhes sobre concentração de renda, veja os seguintes vídeos do Prof. Marcelo Neri da FGV
Mapa da Riqueza
Mapa da Pobreza
-
Exercício em grupo
Trabalhem em grupo e discutam a solução com os demais integrantes do grupo. Lembrem-se que, apesar de resolvido em grupo, a submissão das respostas é individual. Depois de resolver o ED08, leia o artigo disponível na Fundação Getúlio Vargas sobre a desigualdade de renda do trabalho observada no Brasil (medida segundo o índice de Gini em 2020) e, juntamente com os colegas do seu grupo, resuma numa única frase qual a principal informação extraída desse artigo.