Contorno da seção
-
Aula 4
Tabelas e gráficos de frequência
-
Distribuição de probabilidades para variáveis contínuas
para intervalos de x limitados a valores entre A e B
- Distribuição Uniforme
- Distribuição Beta
para intervalos infinitos
- Cauchy
- Weibull
- Pareto
- Logística
- Log-normal
- Normal
e para intervalos semi-infinitos
- Distribuição Gama
- Chi-quadrado (caso especial da Gama)
- Exponencial (caso especial da Weibull)
A Distribuição Normal
A distribuição normal caracteriza muitos fenômenos aleatórios comuns. A função densidade de probabilidade (fdp), ou densidade de uma variável aleatória contínua, é uma função que descreve a probabilidade relativa de uma variável aleatória assumir um certo valor. A fdp da distribuição normal pode ser definida graficamente e matematicamente da seguinte forma:
onde,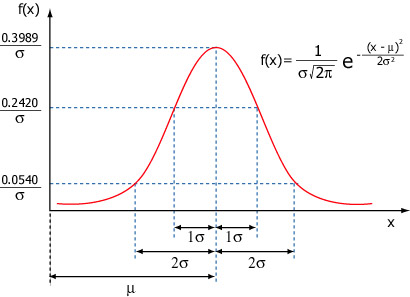
\(-\infty < x > \infty\)
\(E(x)=\mu\)
\(var(x)=\sigma^{2}\)
A notação N(μ, σ) é geralmente utilizada para representar uma distribuição normal com média μ e desvio padrão σ. A importância da distribuição normal se dá também pelo fato da média das amostras tiradas de quaisquer distribuições seguirem sempre distribuição normal. Observe as seguintes características da fdp normal:


Clique AQUI para download de uma versão PDF destes apontamentos e resolva as questões propostas no Estudo Dirigido 7 (ED07, no canto superior deste bloco).