NoSQL: Teorema CAP, MongoDB, CouchDB
Distributed SQL 1.4
Inhaltsübersicht
1. WEB Group Discussion - Spanner (Distributed SQL 1.4) [Bearbeiten]
1.1.1. Students List
1.1.2. Main DB Features
1.1.3. Does It Implement CA, CP, or AP? Why?
1.1.4. DB Advantages
1.1.5. DB Disadvantages
1.1.6. Application Niches
WEB Group Discussion - Spanner (Distributed SQL 1.4) [Bearbeiten]

Students List
- Ana Vitoria Gouveia Freitas (11370196)
- Bernardo Marques Costa (11795551)
- Diógenes Silva Pedro (11883476)
- Fernando Henrique Paes Generich (11795342)
- Gabriel Alves Kuabara (11275043)
- Gabriel Freitas XImenes de Vasconcelos (11819084)
- Gabriel Victor Cardoso Fernandes (11878296)
- Guilherme Lourenço de Toledo (11795811)
- Guilherme Machado Rios (11222839)
- Matheus Silva (11847429)
- Milena Correa da Silva (11795401)
- Pedro Henrique Borges Monici (10816732)
- Raíssa Torres Barreira (11796336)
- Rodrigo Lopes Assaf (11795530)
- Sofhia de Souza Goncalves (11735035)
- Victor Henrique de Sa Silva (11795759)
Link para a apresentação
Main DB Features
Sobre o SQL Distribuído, temos as seguintes features como principais:
- Resistente a falhas e continuamente disponível: devido a distribuição dos dados do banco repetidamente em diversos nós físicos, serviços críticos permanecem disponíveis durante falhas de nós, zonas, regiões e centros de dados, bem como manutenção do sistema com rápida falha.
- Horizontalmente escalável: As equipes de operações podem escalar sem esforço, mesmo sob carga pesada, sem tempo de parada, simplesmente adicionando nós a um aglomerado e voltando a escalar quando a carga for reduzida.
- Geograficamente distribuído: Os operadores podem fazer uso de replicação de dados síncronos e assíncronos e geo-particionamento para implantar bancos de dados em configurações geo-distribuídas.
- Características compátiveis com SQL e RDBMS: Os desenvolvedores não precisam mais escolher entre a escalabilidade horizontal dos sistemas nativos da nuvem, as garantias ACID (atomicidade, consistência, isolamento, durabilidade) e forte consistência dos Sistemas de Gerenciamento de Banco de Dados tradicionais.
- Híbrido e Multi-nuvem pronta: As organizações podem implantar e executar infra-estrutura de dados em qualquer lugar - e evitar o travamento em qualquer fornecedor específico de nuvens.
Does It Implement CA, CP, or AP? Why?
O Spanner clama ser um sistema “CA efetivo” mesmo operando sobre uma grande área. Sua consistência é constante e atinge uma disponibilidade de mais de 5 9s (99.999%) dos casos. No caso onde ocorra interrupções, o Spanner escolhe a consistência acima da disponibilidade.
Em termos do CAP o Spanner é tratado como um CA, porém com uma resposta mais "purista" as partições podem acontecer e elas realmente acontecem. Quando isso acontece o Spanner escolhe C e releva A. Então tecnicamente temos um sistema CP.
O Spanner faz um grande uso de sincronização de clocks por meio de GPS clocks e atomic clocks para garantir uma consistência global. Isso só é garantido por meio da infraestrutura de sistema distribuído e de cloud system trazida pelo projeto TrueTime. Esse sistema é implementado graças ao predomínio da infraestrutura da Google em todo o mundo, fazendo com que o sistema seja distribuído, mas sobre o controle de uma mesma empresa sobre a rede.
DB Advantages
Para bancos de dados SQL distribuídos, temos as seguintes vantagens:
- Garante os benefícios da semântica relacional e do SQL com escalonamento ilimitado.
- Permite iniciar com qualquer tamanho e ajustar o escalonamento sem limites de acordo com o aumento das necessidades.
- Alta disponibilidade (99.999%)
- Permite transações de alto desempenho com consistência forte em todas as regiões e continentes. Otimiza o desempenho ao fragmentar automaticamente os dados com base na carga da solicitação e no tamanho dos dados.
- Extremamente recomendado quando a prioridade é disponibilidade e consistencia.
DB Disadvantages
Em um sistema de gerenciamento de bancos de dados distribuídos:
- Processamento de consultas distribuídas e otimização necessita de algoritmos adequados.
- Seu controle e gerência devem trabalhar de forma integrada.
- Dificuldade no seu desenvolvimento, manutenção e gerenciamento.
- Deve considerar a fragmentação dos dados, alocação dos fragmentos em lugares específicos e a replicação de dados.
- Como é uma área relativamente nova ainda não há tantos casos (ou experiências) práticos de seu uso disponíveis como exemplo.
- Deve considerar a fragmentação dos dados, alocação dos fragmentos em lugares específicos e a replicação de dados.
- Dificuldade em evitar que erros ocorridos nas máquinas ou na rede atrapalhem o sistema.
- Garantir a segurança dos dados compartilhados entre as máquinas através do sistema.
- Fragmentos de banco de dados remotos devem ser seguros e, como eles não são centralizados então os lugares remotos também devem ser seguros.
- Fragmentos de banco de dados remotos devem ser seguros e, como eles não são centralizados então os lugares remotos também devem ser seguros.
- Custo geral
- Manutenção, aquisição, hardware, rede/comunicação, mão de obra, etc.
- O aumento da complexidade e uma infraestrutura mais extensa significa custo extra de trabalho.
- Manutenção, aquisição, hardware, rede/comunicação, mão de obra, etc.
- Controle de integridade
- Todas as alterações feitas nos dados de um site devem ser refletidas em todos os sites.
- Todas as alterações feitas nos dados de um site devem ser refletidas em todos os sites.
- Falta de padrões
- Não existem regras e protocolos padrão para converter um DBMS centralizado em um grande DBMS distribuído.
- Não existem regras e protocolos padrão para converter um DBMS centralizado em um grande DBMS distribuído.
Sobre o Spanner:
- O Spanner é caro de se manter, dado que precisa de máquinas com um clock específico (faz uso pesado de sincronização de clock assistida por hardware usando clocks GPS, que combina tempos de diferentes satélites com estimativa de erro).
- Devido a esse processo de sincronização, as latências num geral são maiores.
- Não é ideal para casos de uso com muita necessidade de escrita no banco.
- A API de escrita do banco não usa estritamente SQL.
- É difícil a coalocação de outros serviços no banco.
Application Niches
Bases de dados com SQL Distribuído são mais úteis como lojas operacionais nas quais escala, disponibilidade e requisitos de recuperação de desastres excedem as capacidades de uma base de dados relacional mais tradicional.
Quanto ao Spanner, temos muitas empresas grandes que o utilizam, e como foi desenvolvido pela Google, que desenvolve outras ferramentas, empresas que já utilizam ferramentas da Google em outras áreas a preferem por maior compatibilidade. Entre as empresas que o utilizam temos:
- Vimeo
- Sabre
- Macy's
- Americanas
Para casos gerais, podemos destacar o uso do SQL distribuído para três setores:
- Dados de comércio digital: Utilizado para mediar as interações do usuário, transições e gerenciamento de produtos.
- Serviços financeiros: Utilizado para gerenciar trocas e transações, prevenção de fraudes e informações sobre compradores e suas contas.
- Comércios no geral: Informações sobre a cadeia de suprimentos, inventário, finanças, compradores e contas.
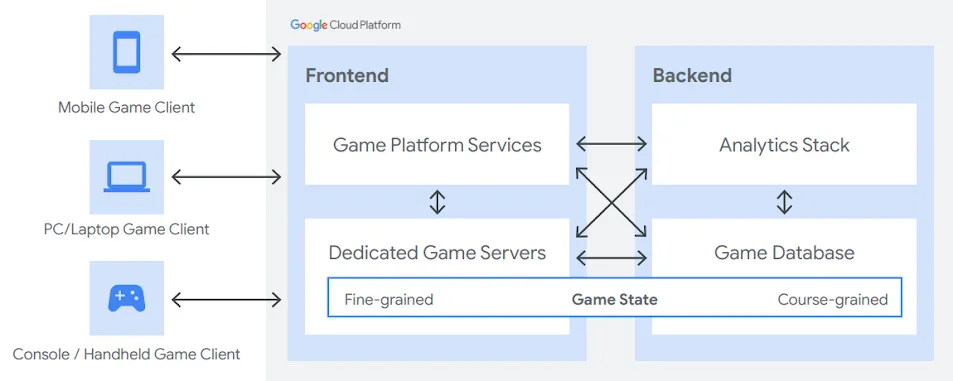
Além de se encaixar nestes usos, o Spanner tem um destaque para desenvolvedores de jogos de multiplayer global. Por ser um serviço de banco de dados SQL distribuído e globalmente escalonável (separa a computação do armazenamento), é possível o escalonamento dos recursos de processamento à parte do armazenamento. Devido à natureza do escalonamento distribuído da arquitetura do Spanner, ele é uma solução ideal para cargas de trabalho imprevisíveis, como jogos on-line.